NUMA on Keeneland
Introduction
NUMA stands for “non-uniform memory access,” but more generally it can refer to the physical layout of compute resources within a system and the corresponding effects on application performance. For example, in multicore and multi-socket systems, there may be varying access distances between processors and memory, GPUs, network interfaces, etc. Therefore, when multiple threads from a single application are running on different processors, each thread may differ in how quickly it can access off-chip resources. Most of the material below was presented by Jeremy Meredith at the Keeneland SC12 tutorial 11/2012.
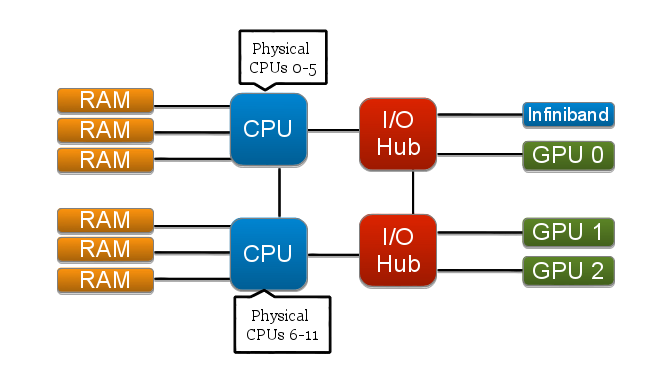
Below is a diagram of a single compute node on KIDS. CPUs 0-5 make up NUMA “node 0,” and CPUs 6-11 are NUMA “node 1,” as can be seen by using the numactl command (explained more below).
unix> numactl --hardware available: 2 nodes (0-1) node 0 size: 12088 MB node 0 free: 10664 MB node 1 size: 12120 MB node 1 free: 11709 MB node distances: node 0 1 0: 10 20 1: 20 10
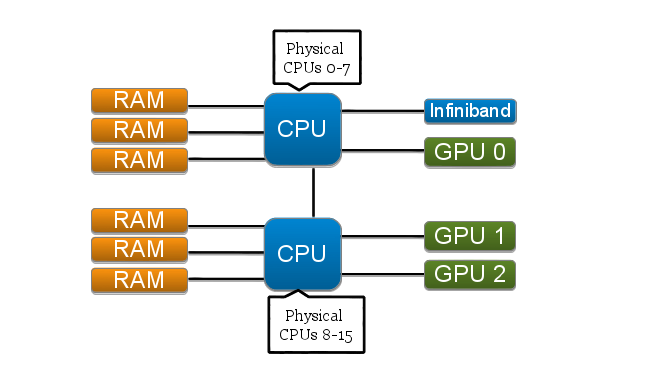
Similarly, for KFS we see that there are still two NUMA nodes. Even though the reported distances between these nodes are the same as on KIDS, that the path between each node and the off-chip resources such as GPUs and the infiniband device is shorter due to the absence of the I/O hub that is present in KIDS.
unix> numactl --hardware available: 2 nodes (0-1) node 0 cpus: 0 1 2 3 4 5 6 7 node 0 size: 16349 MB node 0 free: 6186 MB node 1 cpus: 8 9 10 11 12 13 14 15 node 1 size: 16383 MB node 1 free: 14906 MB node distances: node 0 1 0: 10 20 1: 20 10
NUMA Control
There are several ways to influence the NUMA behavior of an application. NUMA can be controlled within the application code using libnuma, at runtime using numactl, or in some MPI implementations that have NUMA controls built in.
numactl on KFS:
unix> numactl
usage: numactl [--interleave=nodes] [--preferred=node]
[--physcpubind=cpus] [--cpunodebind=nodes]
[--membind=nodes] [--localalloc] command args ...
numactl [--show]
numactl [--hardware]
numactl [--length length] [--offset offset] [--shmmode shmmode]
[--strict]
[--shmid id] --shm shmkeyfile | --file tmpfsfile
[--huge] [--touch]
memory policy | --dump | --dump-nodes
unix> numactl -show
policy: default
preferred node: current
physcpubind: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
cpubind: 0
nodebind: 0
membind: 0
The NUMA behavior of MPI applications can be controlled at runtime even if NUMA support it is not directly built into the MPI implementation. To do this, the application is wrapped with a script that uses numactl to launch the processes with the desired bindings.
unix> mpirun ./prog_with_numa.sh
In the prog_with_numa.sh script:
if[[$OMPI_COMM_WORLD_LOCAL_RANK == “0”]] then numactl --membind=0 --cpunodebind=0 ./prog -args else numactl --membind=1 --cpunodebind=1 ./prog -args fi
NUMA performance impact
A detailed study of NUMA impacts on application performance was done and can be found in the following publications:
Spafford, K., Meredith, J., Vetter, J. Quantifying NUMA and Contention Effects in Multi-GPU Systems. Proceedings of the Fourth Workshop on General-Purpose Computation on Graphics Processors (GPGPU 2011). Newport Beach, CA, USA.
Meredith, J., Roth, P., Spafford, K., Vetter, J. Performance Implications of Non-Uniform Device Topologies in Scalable Heterogeneous GPU Systems. IEEE MICRO Special Issue on CPU, GPU, and Hybrid Computing. October 2011.
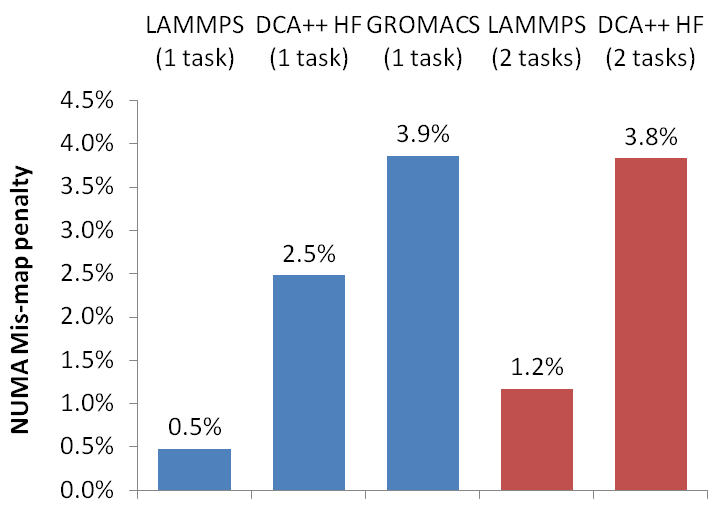
A couple of highlights from these studies are the sizes of the effects that NUMA mapping has on KIDS and KFS, as well as some “real world” results of NUMA usage.
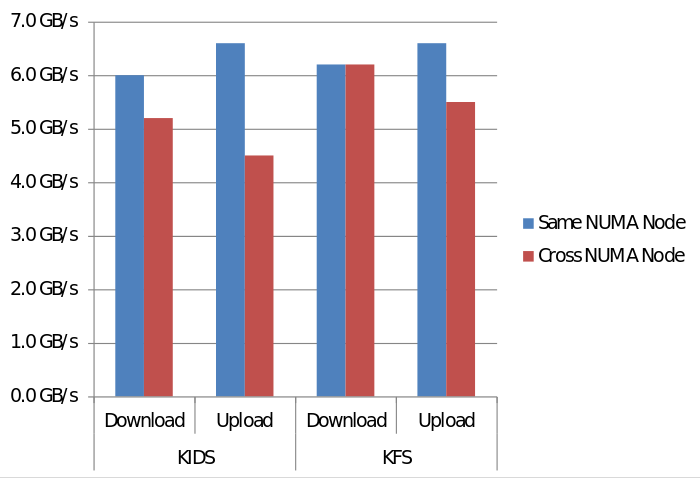
Here we can see how NUMA mapping affects OpenCL bandwidth on KIDS and KFS.
And similarly this graph shows how NUMA mapping affects OpenCL latency on KIDS and KFS.
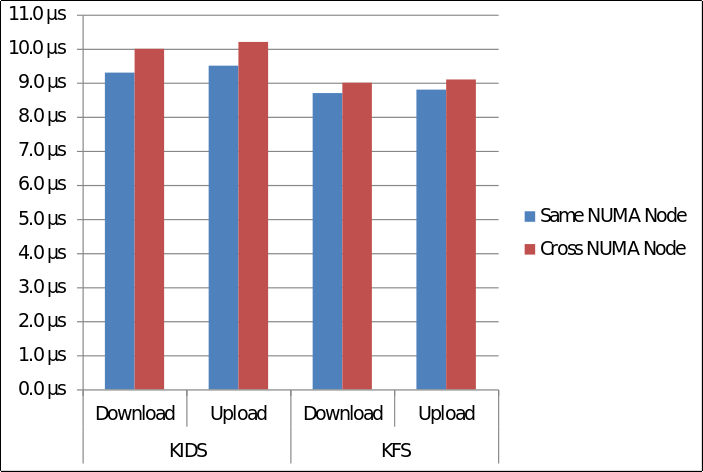
To see how these results translate to actual calculations, we want to know the overall cost of using the incorrect NUMA mapping. All of the following tests were done on KIDS.
In this table, the penalty for using the incorrect NUMA mapping is shown for some common computational kernels, as implemented in the SHOC benchmark suite.
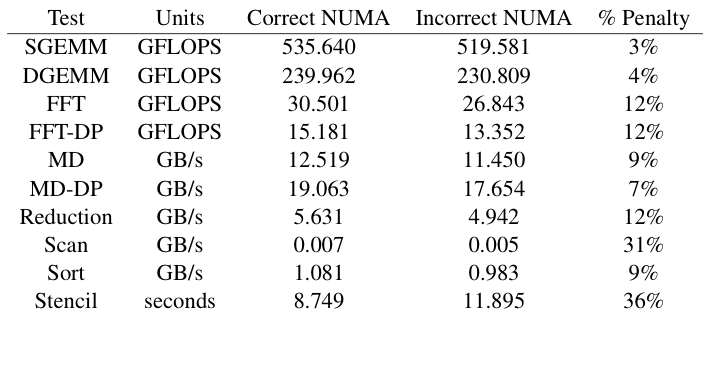
As might be expected, the penalty is greater for those kernels that have a lower computational density.
Here are similar results for three full applications, again showing the penalty for incorrect NUMA mapping.